Con l’uscita di Windows Server 2016 molte infrastrutture prenderanno la decisione di aggiornare i propri Domain Controller in particolar modo se ancora ne hanno alcuni basati su Windows Server 2003. La dismissione dei Domain Controller Windows Server 2003 consente infatti di trarre vantaggio dalle numerose funzionalità che sono state introdotte in Active Directory rispetto a Windows Server 2003 che rappresenta la versione di sistema operativo più datata da cui è ancora possibile eseguire la migrazione. Nel quarto dei quattro articoli sull’analisi le problematiche relative all’aggiornamento di un’infrastruttura Active Directory basata su Domain Controller Windows Server 2003 verrà analizzata la migrazione della replica SYSVOL da FRS a DFS.
Il primi tre articoli sono disponibili ai seguenti:
- Upgrade domain controller a Windows Server 2016 Parte 1 di 4
- Upgrade domain controller a Windows Server 2016 Parte 2 di 4
- Upgrade domain controller a Windows Server 2016 Parte 3 di 4
Argomenti
- Vantaggi della replica SYSVOL tramite DFS e pianificazione della migrazione da FRS a DFS
- Verifica dei prerequisiti e della funzionalità della replica FRS
- Migrazione del dominio nello stato Prepared
- Migrazione del dominio nello stato Redirect
- Migrazione del dominio nello stato Eliminated
- Conclusioni
Vantaggi della replica SYSVOL tramite DFS e pianificazione della migrazione da FRS a DFS
I Domain Controller utilizzano la directory condivisa SYSVOL per replicare tra loro gli script di logon e i file delle Group Policy. In Windows Server 2000 e Windows Server 2003 la replica della directory SYSVOL avviene tramite File Replication Service (FRS). A partire da Windows Server 2008 viene utilizzata invece la replica DFS se il livello funzionale del domino è Windows Server 2008, in caso contrario si continua ad utilizzare FRS.
Questo significa che nell’infrastruttura di esempio dal momento che il livello funzionale è Windows Server 2003 la replica della directory SYSVOL avviene tramite FRS e non tramite la nuova replica DFS che offre maggior efficienza, maggior scalabilità, utilizza l’algoritmo Remote Differential Compression (RDC) che riduce l’utilizzo della banda di rete e ha un meccanismo di auto ripristino da eventuali corruzioni.
Di seguito lo schema dell’infrastruttura a cui faremo rifermento in cui è presente un DC Windows Server 2016 VSDC2016 e la replica della SYSVOL avviene tramite l’FRS.
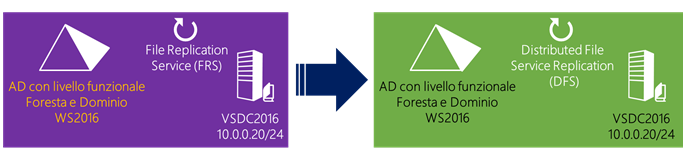
In scenari come quello dell’esempio risulta quindi necessario eseguire manualmente la migrazione dalla replica FRS alla replica DFS, sino a che la migrazione non è terminata non devono essere apportate modifiche a script di logon e Group Policy. Durate la migrazione gli utenti possono continuare aa operare e la durata della migrazione è correlata alla replica di AD in quanto la SYSVOL DFSR avviene durante una schedulazione della replica AD, questo significa che la DFRS legge e scrive gli stati ogni 5 min su ogni Domain Controller. Quindi la migrazione può impiegare pochi minuti in piccoli domini, ma alcune ore o giorni in domini estesi.
Per consentire la diagnostica del DFS è consigliabile installare il tool DFS Management la funzionalità Remote Server Administration Tools – Feature Administration Tools – Role Administration Tools – File Services Tools – DFS Management Tools.
Per maggiori informazioni si veda SYSVOL Replication Migration Guide: FRS to DFS Replication e i seguenti post dello Storage Team:
- SYSVOL Migration Series: Part 1 – Introduction to the SYSVOL migration process
- SYSVOL Migration Series: Part 2 – Dfsrmig.exe: The SYSVOL migration tool
- SYSVOL Migration Series: Part 3 – Migrating to the Prepared State
- SYSVOL Migration Series: Part 4 – Migrating to the ‘REDIRECTED’ state
- SYSVOL Migration Series: Part 5 – Migrating to the ‘ELIMINATED’ state
Per le novità introdotte nella replica DFS in Windows Server 2012 si veda DFS Replication Improvements in Windows Server 2012, mentre in Windows Server 2016 e Windows 10, come indicato in What’s New in File and Storage Services in Windows Server 2016 Technical Preview, è stato implementato un hardening dell’SMB per le connessioni a SYSVOL e NETLOGON su Domain Controller richiedendo l’SMB signing e la mutua autenticazione, come ad esempio Kerberos, per ridurre la probabilità di attacchi man-in-the-middle (per maggiori informazioni si vedano la KB3000483 – MS15-011: Vulnerability in Group Policy could allow remote code execution: February 10, 2015 e il post MS15-011 & MS15-014: Hardening Group Policy).
Verifica dei prerequisiti e della funzionalità della replica FRS
Per verificare che la replica FRS funzioni correttamente è possibile eseguire i seguenti controlli:
-
Verificare la funzionalità delle share NETLOGON e SYSVOL su ogni Domain Controller mediante i comandi:
- net share
- dcdiag /test:frssysvol
- dcdiag /test:netlogons
- dcdiag /e /test:sysvolcheck /test:advertising
- Verificare su ogni Domain Controller che il volume su cui risiede la share SYSVOL abbia almeno lo spazio necessario pari alla dimensione della SYSVOL più 10%.
- Controllare la funzionalità della replica FRS tramite il tool FRSDIAG (si vedano le indicazioni nel seguente Verifying File Replication during the Windows Server 2008 DFSR SYSVOL Migration – Down and Dirty Style)
- Verificare su ogni Domain Controller (nell’esempio esiste solo VMDC2016) che la replica Active Directory funzioni correttamente tramite il comando repadmin /ReplSum.
- Verificare su ogni Domain Controller che la chiave di registro HKLM\System\CurrentControlSet\Services\Netlogon\Parameters contenga il valore SysVol impostato a [drive:\]Windows_folder\SYSVOL\sysvol e che contenga il valore SysvolReady impostato a 1.
- Controllare che su ogni Domain Controller il servizio Replica DFS (DFSR) sia avviato e impostato per l’avvio automatico.
- Il built-in Administrators group deve avere i privilegi di “Manage Auditing and Security Log” su tutti i Domain Controller, come da impostazione di default (a rigaurdo si veda la KB2567421 DFSR SYSVOL Fails to Migrate or Replicate, SYSVOL not shared, Event IDs 8028 or 6016).
Per poter utilizzare la replica DFS occorre aumentare il livello funzionale portandolo almeno a Windows Server 2008, ma se si suppone di inserire nell’infrastruttura solo Domain Controller Windows Server 2016 o superiori conviene portare a Windows Server 2016 il livello funzionale della foresta per beneficiare di tutte le novità introdotte. E’ possibile elevare il livello funzionale del dominio e della foresta tramite il tool i Servizi di dominio di Active Directory come visto precedentemente oppure usare i seguenti comandi PowerShell:
#Raise livello funzionale del dominio a Windows 2016
Set-ADDomainMode -Identity devadmin.local -DomainMode Windows2016
#Verifica livello funzionale del dominio corrente
(Get-ADDomain).DomainMode
#Raise livello funzionale della foresta a Windows 2016
Set-ADForestMode -Identity devadmin.local -ForestMode Windows2016
#Verifica del livello funzionale della foresta corrente
(Get-ADForest).ForestMode
Per verificare che l’aumento del livello funzionale di dominio sia avvenuto correttamente è possibile controllare che sia stato registrato il seguente evento:
- Registro Directory Services – Evento d’informazioni ActiveDirectory_DomainService 2039
Per verificare che l’aumento del livello funzionale della foresta sia avvenuto correttamente è possibile controllare che sia stato registrato il seguente evento:
- Registro Directory Services – Evento d’informazioni ActiveDirectory_DomainService 2040
Migrazione del dominio nello stato Prepared
Prima di eseguire la migrazione del dominio nello stato Prepared eseguire un backup del system state dei Domain Controller nell’infrastruttura (nell’esempio esiste solo VMDC2016). Terminato il backup dei system state dei Domain Controller nell’infrastruttura, che consentirà di rispristinare la situazione precedente nel caso subentrassero problemi, è possibile impostare il global migration state a Prepared eseguendo da un Domain Controller (preferibilmente il PDC Emulator e comunque non un Read Only Domain Controller) il comando:
dfsrmig /setglobalstate 1
Per verificare che il global migration state è stato impostato a Prepared è possibile utilizzare il seguente comando:
dfsrmig /getglobalstate
Per verificare che tutti i Domain Controller abbiano raggiunto lo stato Prepared è possibile utilizzare il seguente comando:
dfsrmig /getmigrationstate
Per verificare che il global migration state è stato impostato a Prepared è possibile controllare che sia stato registrato il seguente evento:
- Registro DFS Replication – Evento d’informazioni DFSR 8014
Verificare che su ogni Domain Controller sia stata creata la directory %SystemRoot%\SYSVOL_DFSR e che il contenuto delle directory domain e sysvol in %SystemRoot%\SYSVOL sia stato copiato in %SystemRoot%\SYSVOL_DFSR.
Utilizzate il tool DFS Management per creare un report diagnostico per la directory SYSVOL_DFSR tramite la seguente procedura:
- Selezionare il nodo Replication – Domain System Volume
- Verificare nel Tab Memeberships che per tutti i Domain Controller sia abilitata la replica per il path %SystemRoot%\SYSVOL_DFSR\domain.
- Selezionare Actions – Create Diagnostics Report.
- Creare un Health report, un
Propagation test e un Propagation report verificando che non vi siano errori.
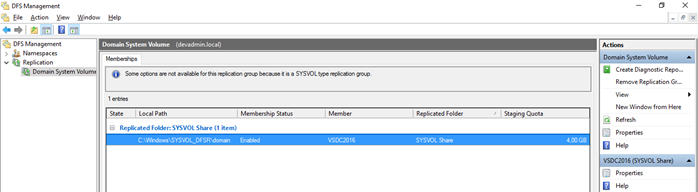
Nello stato di Prepared FRS e DFSR hanno le proprie copie della SYSVOL, le shares SYSVOL e Netlogon si referenziano alla copia FRS, ma è ancora possibile eseguire il rollback tramite il comando:
dfsrmig /setglobalstate 0
Migrazione del dominio nello stato Redirect
Per impostare il global migration state a Redirect eseguire da un Domain Controller (preferibilmente il PDC Emulator e comunque non un Read Only Domain Controller) il comando:
dfsrmig /setglobalstate 2
Per verificare che il global migration state è stato impostato a Redirect è possibile utilizzare il seguente comando:
dfsrmig /getglobalstate
Per verificare che tutti i Domain Controller hanno raggiunto lo stato Redirect è possibile utilizzare il seguente comando:
dfsrmig /getmigrationstate
Per verificare che il global migration state è stato impostato a Redirect è possibile controllare che sia stato registrato il seguente evento:
- Registro Replica DFS – Evento d’informazioni DFSR 8017
Verificare su ogni Domain Controller tramite il comando net share che le share NETLOGON e SYSVOL mappino rispettivamente le directory:
- %SystemRoot%\SYSVOL_DFSR\sysvol\NomeDominioDNS\SCRIPTS
(nell’esempio C:\Windows \ SYSVOL_DFSR\sysvol\devadmin.local\SCRIPTS) - %SystemRoot%\SYSVOL_DFSR\sysvol
Usare il tool DFS Management per creare un report diagnostico per la directory SYSVOL_DFSR utilizzando la procedura descritta precedentemente.
Controllare la funzionalità della replica FRS tramite il tool FRSDIAG (si vedano le indicazioni nel seguente Verifying File Replication during the Windows Server 2008 DFSR SYSVOL Migration – Down and Dirty Style). La replica FRS deve continuare ad essere funzionante per garantire la possibilità di un eventuale roll back.
Nello stato di Redirect FRS e DFSR hanno le proprie copie della SYSVOL e le shares SYSVOL e Netlogon si referenziano alla copia DFS, ma è ancora possibile eseguire il rollback allo stato di Prepared tramite il comando:
dfsrmig /setglobalstate 1
oppure è possibile eseguire il rollback allo stato iniziale tramite il comando:
dfsrmig /setglobalstate 0
Migrazione del dominio nello stato Eliminated
Prima di eseguire la migrazione del dominio nello stato Eliminated eseguire le seguenti operazioni:
- Verificare tramite il comando repadmin /ReplSum che la replica di Active Directory funzioni correttamente.
- Eseguire un backup del system state dei Domain Controller nell’infrastruttura che consentirà di rispristinare la situazione precedente nel caso subentrassero problemi.
Per impostare il global migration state a Eliminated eseguire da un Domain Controller (preferibilmente il PDC Emulator e comunque non un Read Only Domain Controller) il comando:
dfsrmig /setglobalstate 3
Per verificare che il global migration state è stato impostato a Eliminated è possibile utilizzare il seguente comando:
dfsrmig /getglobalstate
Per verificare che tutti i Domain Controller hanno raggiunto lo stato Eliminated è possibile utilizzare il seguente comando:
dfsrmig /getmigrationstate
Per verificare che il global migration state è stato impostato a Eliminated è possibile controllare che sia stato registrato il seguente evento:
- Registro Replica DFS – Evento d’informazioni DFSR 8019
Verificare su ogni Domain Controller tramite il comando net share che le share NETLOGON e SYSVOL mappino rispettivamente le directory:
- %SystemRoot%\SYSVOL_DFSR\sysvol\NomeDominioDNS\SCRIPTS
(nell’esempio C:\Windows \ SYSVOL_DFSR\sysvol\devadmin.local\SCRIPTS) - %SystemRoot%\SYSVOL_DFSR\sysvol
Usare il tool DFS Management per creare un report diagnostico per la directory SYSVOL_DFSR utilizzando la procedura descritta precedentemente.
Verificare che su ogni Domain Controller sia stata rimossa la directory % SystemRoot%\SYSVOL.
Arrestare e disabilitare il servizio FRS su tutti Domain Controller, tranne nel caso in cui l’FRS venisse utilizzato per repliche diverse dalla directory SYSVOL. E’ possibile eseguire tale configurazione tramite i comandi:
sc stop ntfrs
sc config ntfrs start=disabled
Per ulteriori informazioni sulla procedura di migrazione si vedano i post sul blog del team di Directory Services:
- Verifying File Replication during the Windows Server 2008 DFSR SYSVOL Migration – Down and Dirty Style
- The Case for Migrating SYSVOL to DFSR
Conclusioni
La migrazione della replica SYSVOL da FRS a DFS è un’operazione caldamente consigliata dal momento che con Windows Server 2016 l’File Replication Service (FRS) e i livelli funzionali Windows Server 2003 sono deprecati. Inoltre una volta dismessi controller di dominio Windows Server 2003 per avere nell’infrastruttura solo controller di dominio Windows Server 2008 non vi è più alcuna ragione di utilizzare l’FRS per la replica della SYSVOL dal momento che il DFS, come spiegato precedentemente, offre maggiori prestazioni e robustezza.










 Vincenzo Tenisci ha venti anni di esperienza nello sviluppo di applicazioni con tecnologie Microsoft. Quindici anni fa ha iniziato la sua carriera di freelance e adesso collabora con varie societa in Italia come Senior Solution Architect e Trainer MCT. Programma in .NET sin dalla prima beta, ha iniziato a lavorare con SQL Server sin dalla versione 6.5 dal 1996 e SharePoint a partire dal 2003.
Vincenzo Tenisci ha venti anni di esperienza nello sviluppo di applicazioni con tecnologie Microsoft. Quindici anni fa ha iniziato la sua carriera di freelance e adesso collabora con varie societa in Italia come Senior Solution Architect e Trainer MCT. Programma in .NET sin dalla prima beta, ha iniziato a lavorare con SQL Server sin dalla versione 6.5 dal 1996 e SharePoint a partire dal 2003.